
就在Ollama升级到最新版本0.3.13后,它直接打开了AI模型兼容世界:简单来说,ollama现在可以直接运行huggingface上的4.5万多个GGUF格式的模型,一下子感觉格局就打开。
之前,我们在使用Ollama时,需要从Ollama的一个registry上拉模型下来,Ollama自己维护了一个类似docker注册中心服务,先把原始非量化的AI模型进行转换,然后放到这个registry上供Ollama用户下载和运行,也就是说,最坏的情况下Ollama需要维护与Huggingface上同等数量的模型,最好的情况下,Ollama只维护最流行最实用的模型给用户。
Ollama是基于llama.cpp的,后者早已经支持GGUF格式的huggingface模型了,之前Ollama要运行GGUF模型是需要通过创建Modelfile,这次更新终于把这块能力补齐了。
如何运行GGUF模型
非常简单,升级Ollama 0.3.13后,
ollama run hf.co/{username}/{repository}
# 或者
ollama run huggingface.co/{username}/{repository}
# 两个域名都可以
可以试试以下这些:
ollama run hf.co/bartowski/Llama-3.2-1B-Instruct-GGUF
ollama run hf.co/mlabonne/Meta-Llama-3.1-8B-Instruct-abliterated-GGUF
ollama run hf.co/arcee-ai/SuperNova-Medius-GGUF
ollama run hf.co/bartowski/Humanish-LLama3-8B-Instruct-GGUF
运行量化版本
Huggingface上的默认的量化版本为Q4_K_M,如果模型没有该量化版本,则Huggingface会随机选择一个比较合理的量化版本。
指定量化版本的方法:
ollama run hf.co/{username}/{repository}:{quantization}
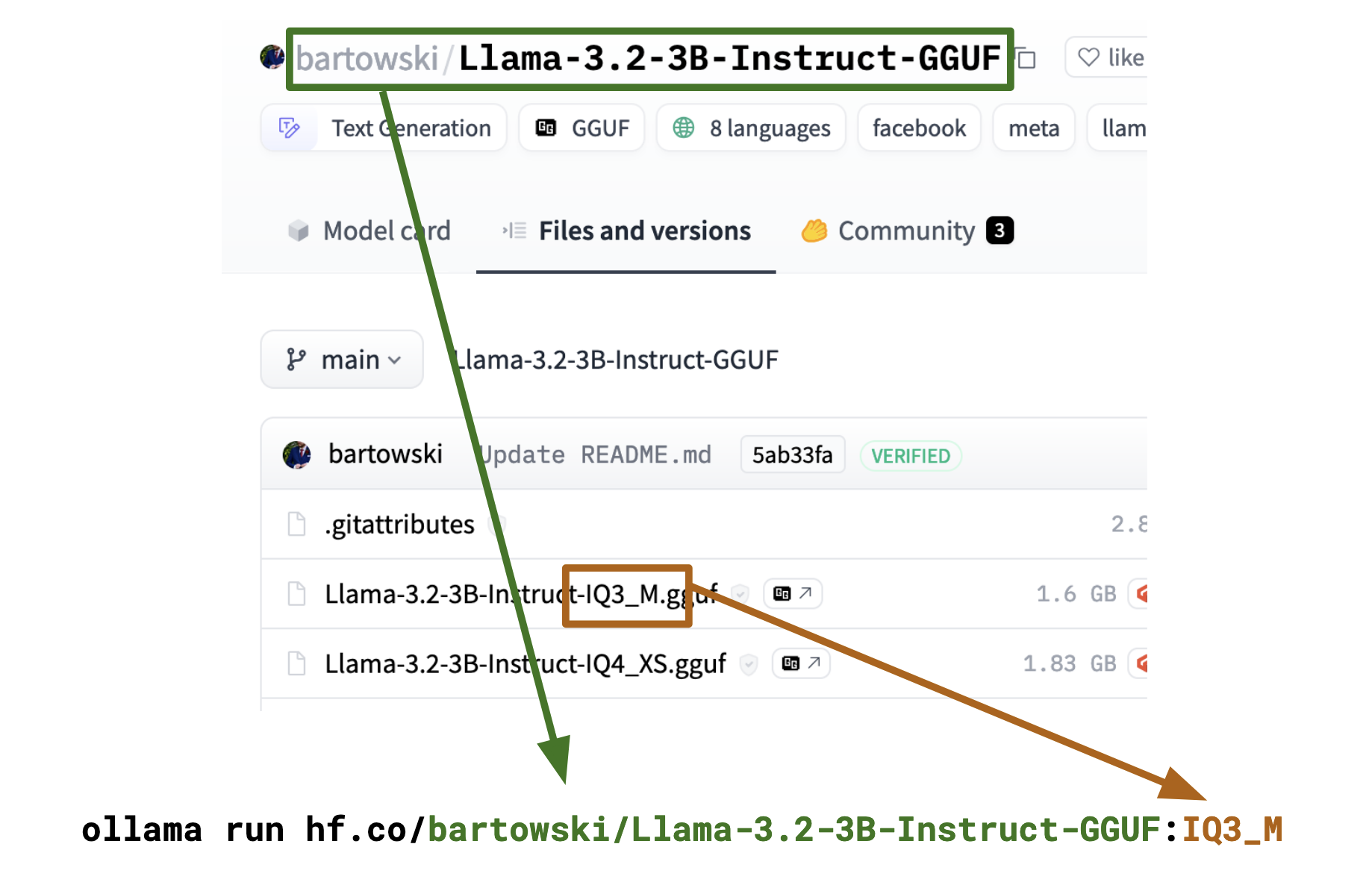 样例:
样例:
ollama run hf.co/bartowski/Llama-3.1-Nemotron-70B-Instruct-HF-GGUF:IQ1_M
# the quantization name is case-insensitive, this will also work
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:iq3_m
# you can also directly use the full filename as a tag
ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Llama-3.2-3B-Instruct-IQ3_M.gguf
约束和限制
经过测试,发现每次运行ollama run都会拉一次GGUF模型下来,会造成空间的浪费。