背景:
随着AI和LLM大模型的发展和成熟,在本机运行大模型已经比较普及,今天我们主要是用Docker来安装ollama前端并且调用ollama3模型。
安装ollama和下载模型
这个比较基础,也可以参考我的另一篇博客
打开https://www.ollama.com/download,下载适合你系统的安装包,安装ollama
安装时,会提示你要下载那个模型,我们可以进入到https://www.ollama.com/library,查看所有可用的模型,这次我们选择ollama3 8B模型,这个模型大小适中,推理和理解能力大概可以与GPT3.5持平,可以运行“ollama run llama3” 或者“ollama pull llama3”来下载模型。

安装OpenWebUI前端
OpenWebUI是一个通用的支持多种LLM的前端应用,可以帮组我们来调用LLM模型
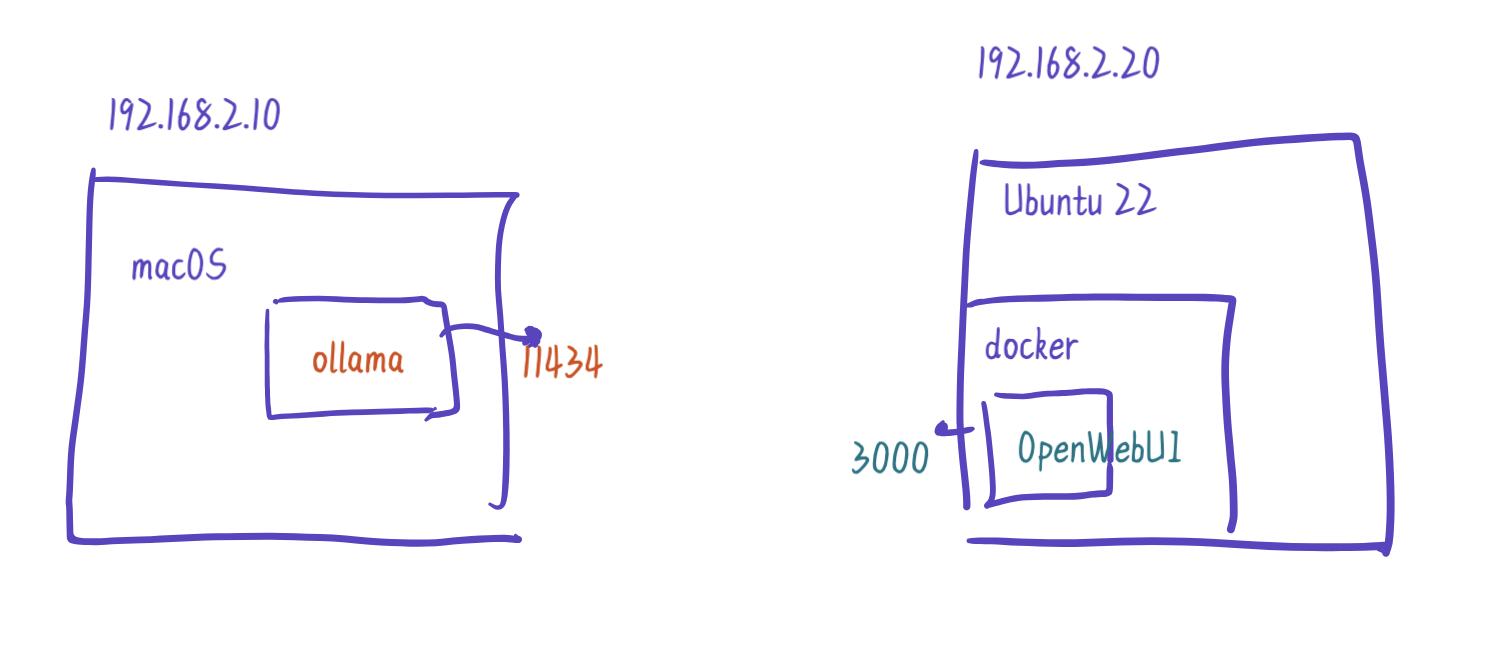
这里有个注意点:就是我在本机安装的ollama和docker,而Open-WebUI是安装在Docker容器里的,所以我们需要注意网络联通性。由于ollama默认运行在11434端口,对于运行在Docker容器中的OpenWebUI来说,它需要访问一个它可以见的服务地址。
以我当前的安装为例,我的macOS的IP是192.168.2.10,我的Docker主机的地址是192.168.2.20, Docker容器需要访问到我macOS的11434端口,所以使用Docker命令安装OpenWebUI时需要指定Base URL:
docker run -d --network=myhome \
-p 3000:8080 \
-v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://192.168.2.10:11434 \
--name open-webui --restart always \
ghcr.io/open-webui/open-webui:main
 测试一下:
测试一下:
这样安装完之后就可以访问了
http://192.168.2.20:3000
首次登录时需要输入email地址sign up,这个地址不会真的给你发email,只是用于记录用户,所以你写任意的email都可以,不过密码得牢记,否则第二次就登不进去了。
登录之后,在页面的中间可以从下拉菜单选择需要的LLM模型,注意根据自己的需要和硬件的能力来选,对于无GPU的我来说,llama3 70b的资源需求量是太高,不过llama3 8b还是可以的