
背景
我经常用Zoom开会,因为我的zoom会议都是自动云端录像的,所以云端的10G存储空间动不动就满了,我需要手动下载再清空云端存储,但是手动一个一个下载又太费时间了
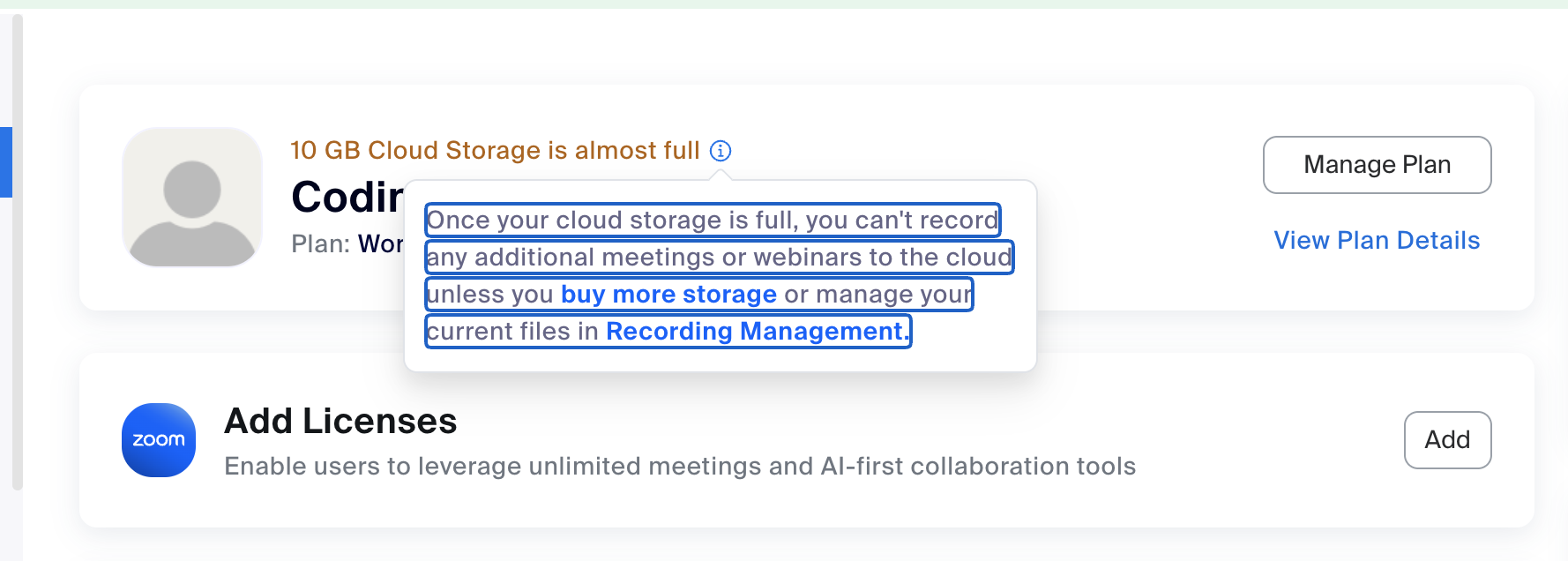
我就用OpenCode+Gemini 3 Pro帮我写下载视频的脚本
设置OpenCode
这一步可以参考我之前的文章用 OpenCode 编排 Agent Skills,打造智能简历优化流水线
配置Zoom访问登陆
这里需要使用Zoom的marketplace来创建一个我们专属的app,
进入Zoom marketplacehttps://marketplace.zoom.us/
右侧选Develop->Build App
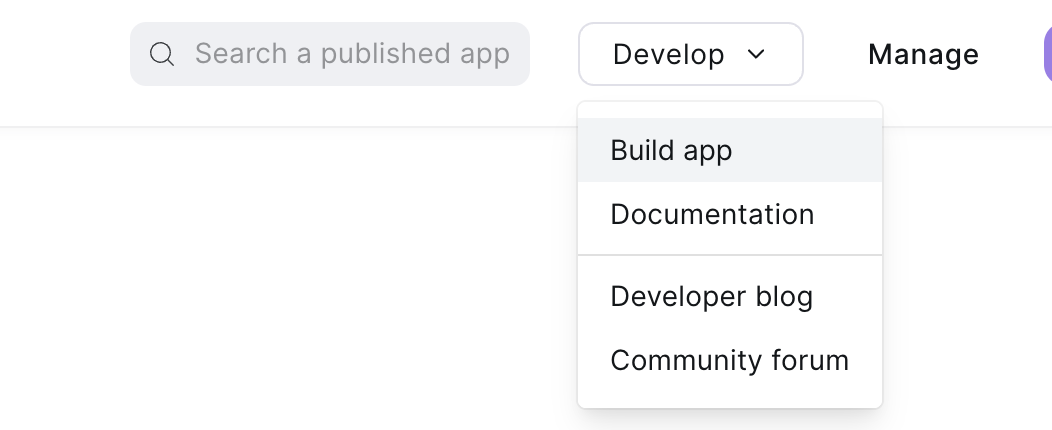
要选“Server-to-Server Auth App"
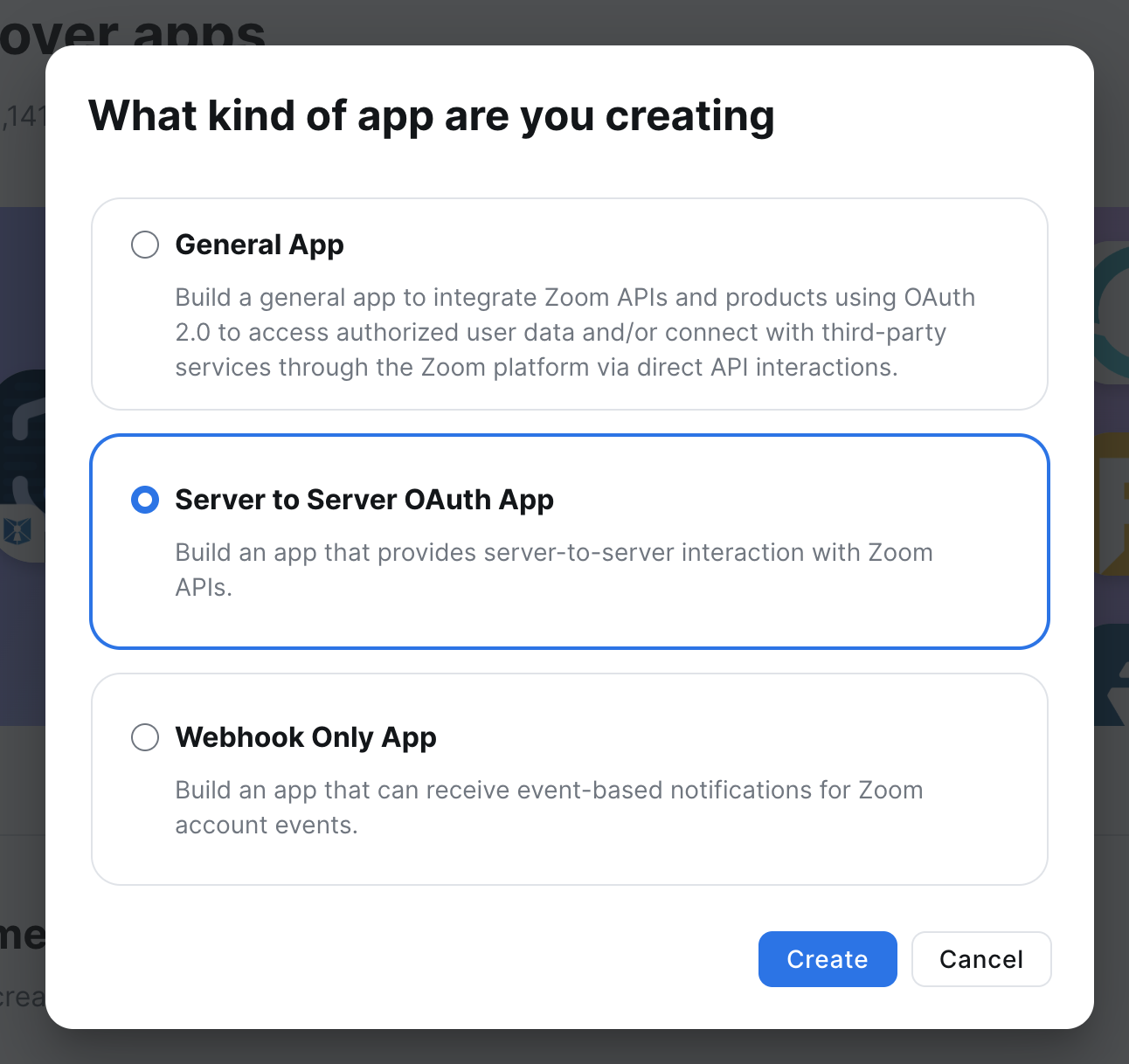
起一个名字
就会得到一组credential,记下来写到".env"文件里
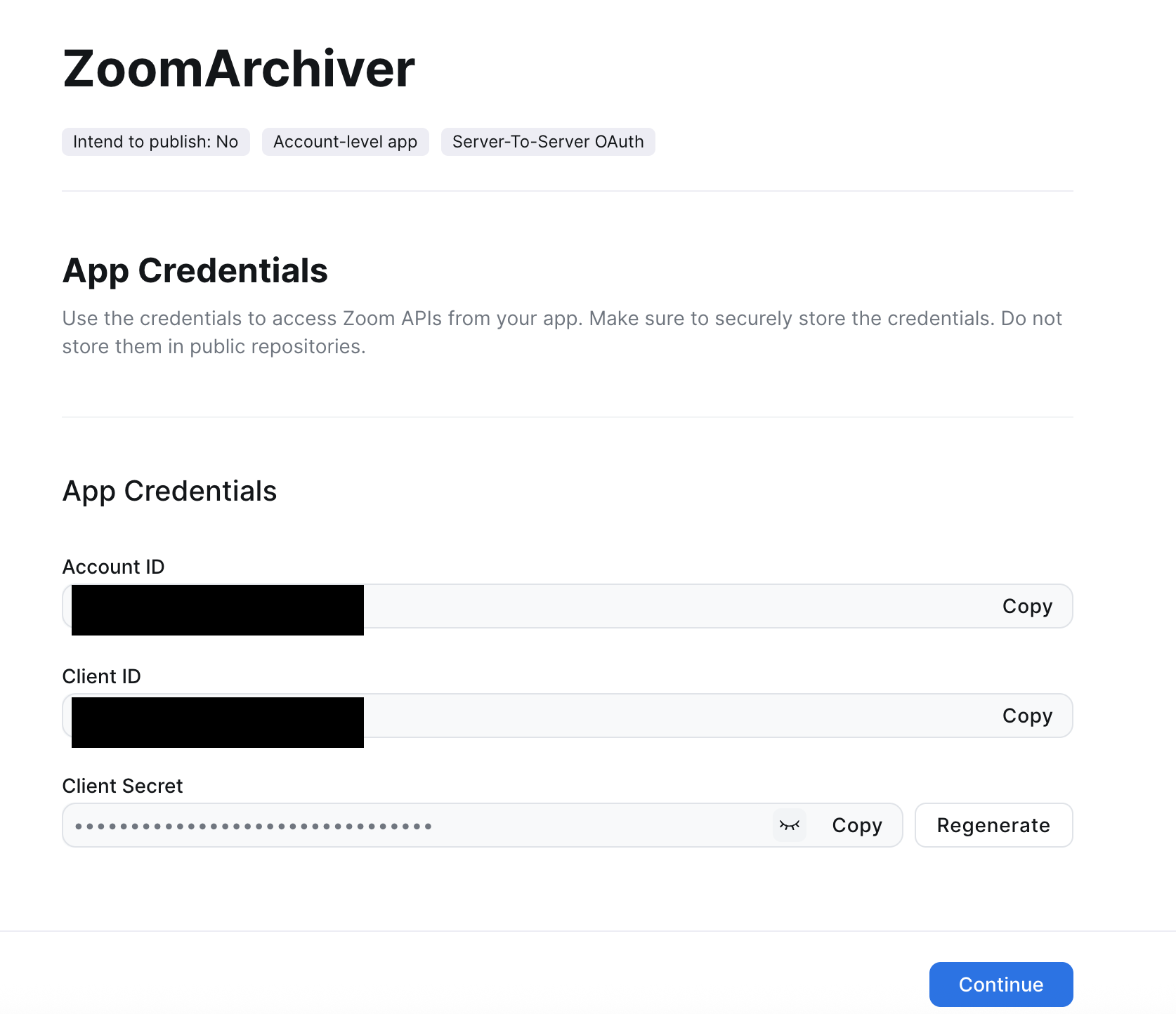
填入Information和Feature,然后在Scope中,点击 “Add Scope”,一定要加入cloud_recording:read:recording:admin, user:read:list_users:admin,user:read:list_users:admin,cloud_recording:read:list_user_recordings:admin,cloud_recording:read:list_account_recordings:admin
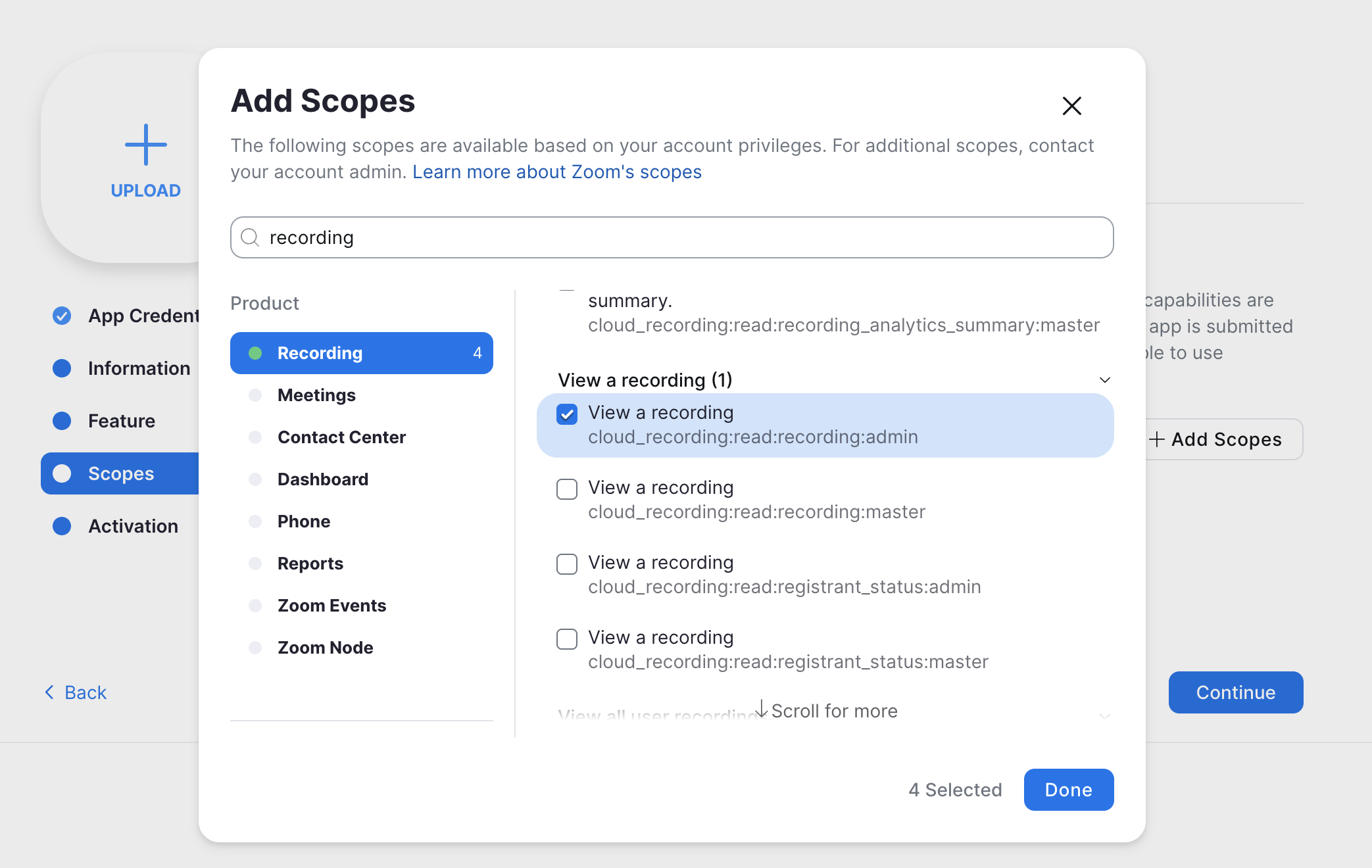
最后可以激活app
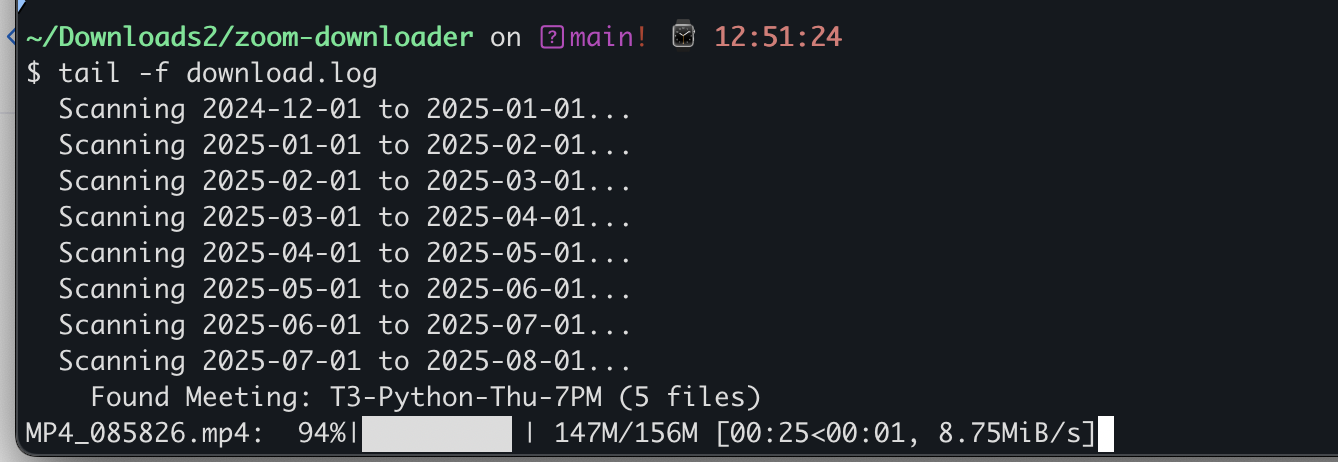
本地配合".env"文件,运行uv run zoom_downloader.py
自动下载效果:
代码供参考
zoom_downloader.py
import os
import requests
import datetime
from dateutil.relativedelta import relativedelta
from dotenv import load_dotenv
import base64
import time
from tqdm import tqdm
import re
# Load environment variables
load_dotenv()
# Configuration
ACCOUNT_ID = os.getenv("ZOOM_ACCOUNT_ID")
CLIENT_ID = os.getenv("ZOOM_CLIENT_ID")
CLIENT_SECRET = os.getenv("ZOOM_CLIENT_SECRET")
START_DATE = os.getenv("START_DATE", "2019-01-01")
DELETE_AFTER_DOWNLOAD = os.getenv("DELETE_AFTER_DOWNLOAD", "False").lower() == "true"
DOWNLOAD_DIR = "downloads"
# API Endpoints
TOKEN_URL = "https://zoom.us/oauth/token"
BASE_URL = "https://api.zoom.us/v2"
def get_access_token():
"""Obtains a Server-to-Server OAuth token."""
if not all([ACCOUNT_ID, CLIENT_ID, CLIENT_SECRET]):
print("Error: Missing credentials in .env file.")
return None
auth_str = f"{CLIENT_ID}:{CLIENT_SECRET}"
b64_auth = base64.b64encode(auth_str.encode()).decode()
headers = {
"Authorization": f"Basic {b64_auth}",
"Content-Type": "application/x-www-form-urlencoded",
}
data = {"grant_type": "account_credentials", "account_id": ACCOUNT_ID}
try:
response = requests.post(TOKEN_URL, headers=headers, data=data)
response.raise_for_status()
return response.json()["access_token"]
except requests.exceptions.RequestException as e:
print(f"Failed to get access token: {e}")
# 'response' might not be defined if the request failed before returning
if "response" in locals() and response and response.text:
print(f"Response: {response.text}")
return None
def get_users(headers):
"""Fetches all users in the account."""
users = []
page_token = ""
print("Fetching user list...")
while True:
params = {"page_size": 300, "next_page_token": page_token}
try:
response = requests.get(f"{BASE_URL}/users", headers=headers, params=params)
response.raise_for_status()
data = response.json()
users.extend(data.get("users", []))
page_token = data.get("next_page_token")
if not page_token:
break
except requests.exceptions.RequestException as e:
print(f"Error fetching users: {e}")
if hasattr(e, "response") and e.response is not None:
print(f"API Response: {e.response.text}")
break
print(f"Found {len(users)} users.")
return users
def get_recordings(headers, user_id, start_date, end_date):
"""Fetches recordings for a specific user within a date range."""
recordings = []
formatted_from = start_date.strftime("%Y-%m-%d")
formatted_to = end_date.strftime("%Y-%m-%d")
try:
params = {
"userId": user_id,
"from": formatted_from,
"to": formatted_to,
"page_size": 300,
}
response = requests.get(
f"{BASE_URL}/users/{user_id}/recordings", headers=headers, params=params
)
if response.status_code == 404:
# User might not exist or has no recordings capability
return []
response.raise_for_status()
data = response.json()
recordings.extend(data.get("meetings", []))
except requests.exceptions.RequestException as e:
print(
f"Error fetching recordings for user {user_id} ({formatted_from} - {formatted_to}): {e}"
)
return recordings
def sanitize_filename(name):
"""Removes illegal characters from filenames."""
return re.sub(r'[\\/*?:"<>|]', "", name)
def download_file(url, file_path, file_size, access_token):
"""Downloads a file with progress bar and resumes if possible."""
# Check if file exists and is complete
if os.path.exists(file_path):
existing_size = os.path.getsize(file_path)
if existing_size == file_size:
print(f"Skipping (already exists): {os.path.basename(file_path)}")
return True
else:
print(f"File incomplete. Re-downloading: {os.path.basename(file_path)}")
# Prepare headers (append access token to download url is usually required for Zoom)
# Note: Zoom download_url usually includes a token, but for S2S we might need to append the access_token query param
# or just use the download_url provided.
# The 'download_url' in the API response usually requires an active session or access_token appended.
download_url_with_token = f"{url}?access_token={access_token}"
try:
response = requests.get(download_url_with_token, stream=True)
response.raise_for_status()
total_size = int(response.headers.get("content-length", 0))
# If API provided file_size, use that as authoritative source if header is missing
if total_size == 0:
total_size = file_size
with (
open(file_path, "wb") as f,
tqdm(
desc=os.path.basename(file_path),
total=total_size,
unit="iB",
unit_scale=True,
unit_divisor=1024,
) as bar,
):
for data in response.iter_content(chunk_size=1024):
size = f.write(data)
bar.update(size)
# Final verification
if os.path.getsize(file_path) == file_size:
return True
else:
print("Warning: Downloaded file size does not match expected size.")
return False
except Exception as e:
print(f"Failed to download {url}: {e}")
return False
def delete_recording_file(headers, meeting_id, recording_id):
"""Deletes a specific recording file from Zoom."""
try:
url = f"{BASE_URL}/meetings/{meeting_id}/recordings/{recording_id}"
response = requests.delete(url, headers=headers)
response.raise_for_status()
print(f"Deleted recording file {recording_id} from Zoom.")
return True
except requests.exceptions.RequestException as e:
print(f"Error deleting recording {recording_id}: {e}")
return False
def main():
print("=== Zoom Downloader Started ===")
# 1. Get Token
token = get_access_token()
if not token:
return
headers = {"Authorization": f"Bearer {token}"}
# 2. Get Users
users = get_users(headers)
# DRY RUN MODE
DRY_RUN = False
if DRY_RUN:
print("\n*** DRY RUN MODE: No files will be downloaded ***\n")
start_dt = datetime.datetime.strptime(START_DATE, "%Y-%m-%d")
end_dt = datetime.datetime.now()
for user in users:
email = user.get("email")
user_id = user.get("id")
print(f"\nProcessing User: {email}")
current_dt = start_dt
while current_dt < end_dt:
# Chunk by 1 month (Zoom API limit)
next_month = current_dt + relativedelta(months=1)
# Don't go into the future
if next_month > end_dt:
next_month = end_dt
print(
f" Scanning {current_dt.strftime('%Y-%m-%d')} to {next_month.strftime('%Y-%m-%d')}..."
)
recordings = get_recordings(headers, user_id, current_dt, next_month)
for meeting in recordings:
topic = sanitize_filename(meeting.get("topic", "Untitled Meeting"))
start_time = meeting.get("start_time", "")[:10] # YYYY-MM-DD
meeting_id = meeting.get("id")
# Create Directory
folder_name = f"{start_time} - {topic} ({meeting_id})"
user_dir = os.path.join(DOWNLOAD_DIR, email, folder_name)
if not DRY_RUN:
os.makedirs(user_dir, exist_ok=True)
print(
f" Found Meeting: {topic} ({len(meeting.get('recording_files', []))} files)"
)
for file_info in meeting.get("recording_files", []):
file_type = file_info.get("file_type", "UNKNOWN")
file_ext = file_info.get("file_extension", "mp4").lower()
recording_id = file_info.get("id")
file_size = file_info.get("file_size", 0)
download_url = file_info.get("download_url")
# Construct nice filename
# e.g. 2023-01-01_1030_MP4_1280x720.mp4
rec_start = file_info.get("recording_start", "")[11:19].replace(
":", ""
)
filename = f"{file_type}_{rec_start}.{file_ext}"
full_path = os.path.join(user_dir, filename)
if download_url:
if DRY_RUN:
print(
f" [DRY RUN] Would download: {filename} ({file_size / 1024 / 1024:.2f} MB)"
)
success = True # Simulate success
else:
success = download_file(
download_url, full_path, file_size, token
)
if success and DELETE_AFTER_DOWNLOAD:
if DRY_RUN:
print(
f" [DRY RUN] Would DELETE from Zoom: {filename}"
)
else:
delete_recording_file(headers, meeting_id, recording_id)
current_dt = next_month
# Small sleep to be nice to API rate limits
time.sleep(0.2)
print("\n=== All Downloads Complete ===")
if __name__ == "__main__":
main()