
背景
起因是有一道中学数学竞赛的题目(9年级,初三),原题是这样的

三角形三个数字之和必须是3的倍数 问这样的组合有多少种
难度
这个题的难度在于他不让你求具体的哪些数字可以构造这样10层的三角形,而是问有多少这样可能的组合
试水
分别让Google Gemini 2.5 Pro 和ChatGPT o3 模型来试试,两者都是多模态推理模型。
Gemini 2.5 Pro
我使用Genimi 2.5 Pro Preview 0506 版本,这个版本是目前号称在STEM领域最强的,并且拥有百万token的上下文长度。
没有什么花里胡哨的提示词,我就直接问了:

Gemini没有任何迟疑,开始分析,分析过程非常长,耗时170多秒!!可以看出,AI分析问题也是从简单的入手,从样例入手的
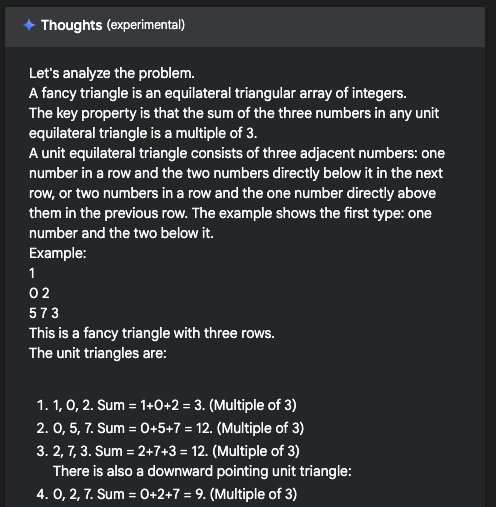
最后Gemini给出的答案是92

ChatGPT o3
OpenAI的多模态推理模型,非常适合STEM问题解决,
还是一样把问题直接丢给它,让它分析解决
o3也用了140多秒进行思考,看来这个题目还是有点难度的,期间不断调用python代码进行验证和尝试
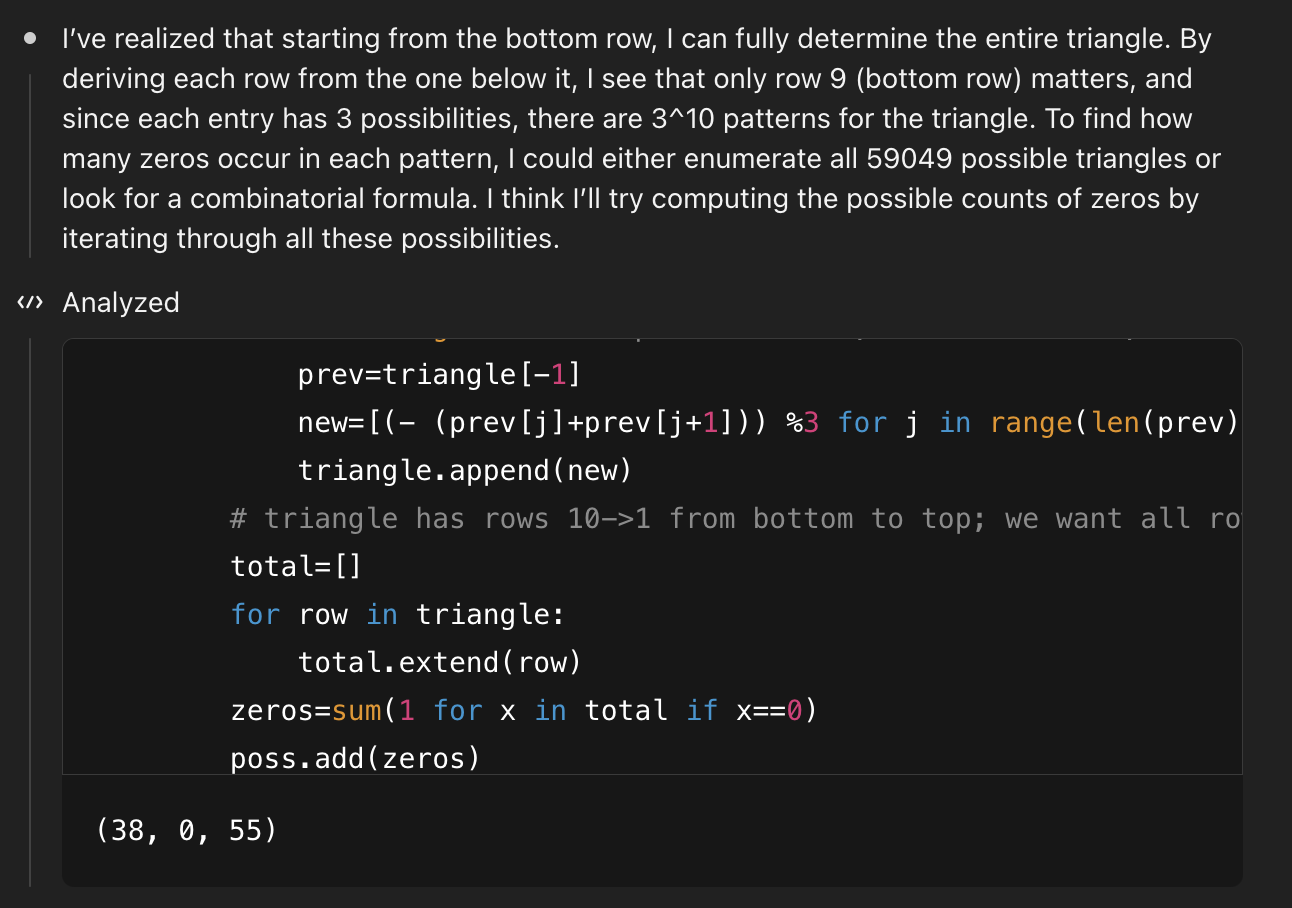
最后,o3得出的结果是 904!

交叉求证
由于两个模型给出了不同的答案,本着耐心教导的原则,我打算进行交叉求证: 分别讲将一个模型的推理过程输入给另一个模型,并且告诉他,“你好好看,你觉得我这个解法对不对呢?”
Gemini 2.5 Pro
不出所料,Gemini 2.5 Pro一眼就发现的o3的算法有问题呢
 斩钉截铁的说,答案就是92
斩钉截铁的说,答案就是92
ChatGPT o3
再来看看o3的,大写的“服气”,o3承认之前的方法是错的,正确答案是92

灵魂拷问:你到底哪里错了?
我继续发问让o3回头看看错在哪里
 AI还是好孩子,知错就改也很快承认了
还整了个中文版给我
AI还是好孩子,知错就改也很快承认了
还整了个中文版给我

结论
这一轮比拼,Gemini 2.5 Pro完胜ChatGPT o3
| Gemini 2.5 Pro | ChatGPT o3 | |
|---|---|---|
| 问题分析的深度 | ✅ | ❌ |
| 理解的程度 | ✅ | ❌ |
| 对问题细节的把握 | ✅ | ❌ |
| 一次性分析正确率 | ✅ | ❌ |
| 面对质疑的坚定 | ✅ | ❌ |
后记
很多宝子不信邪,非要我试试ChatGPT 4.5面向研究用途的大语言模型。我听劝,真去跑一下,哎,还不如o3呢 😂
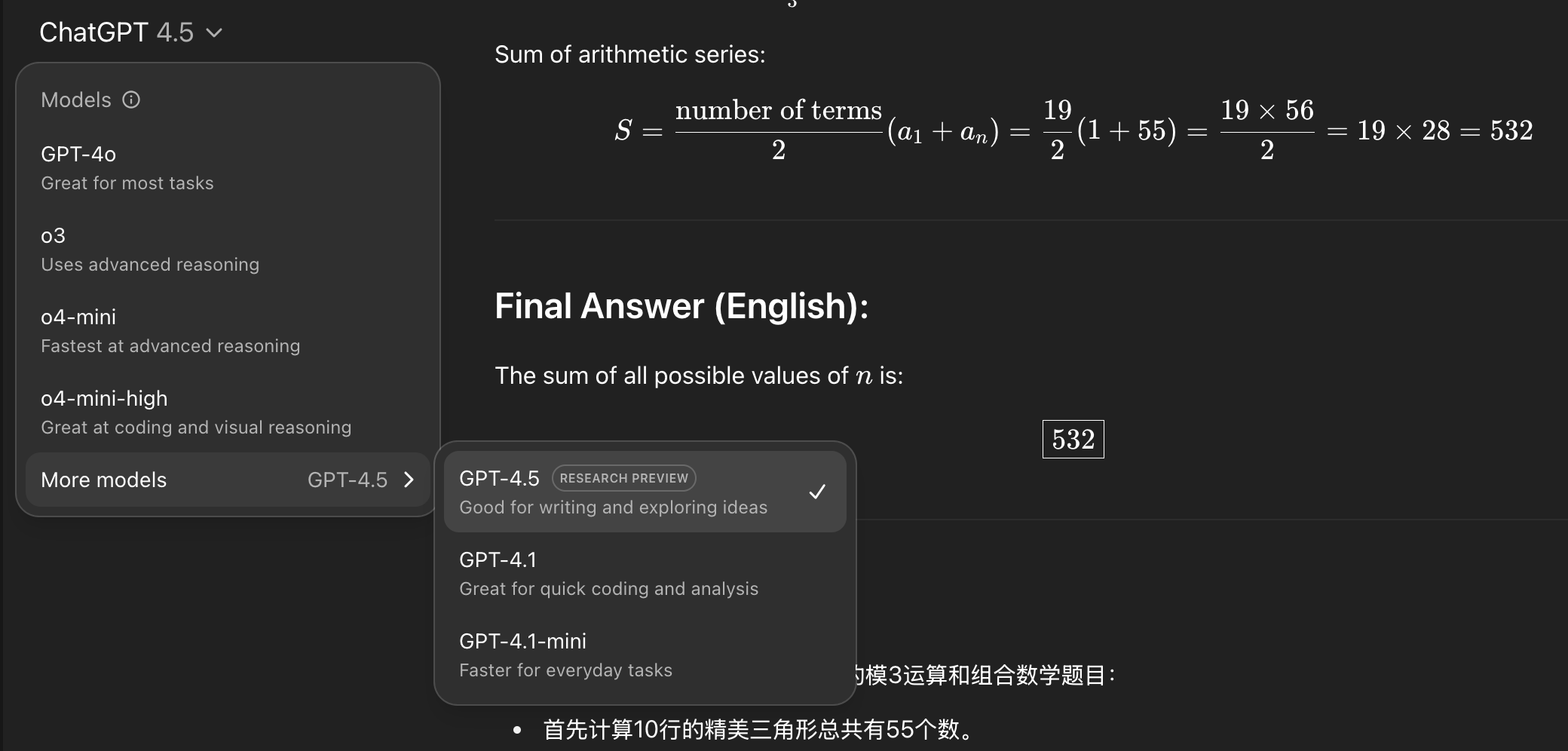
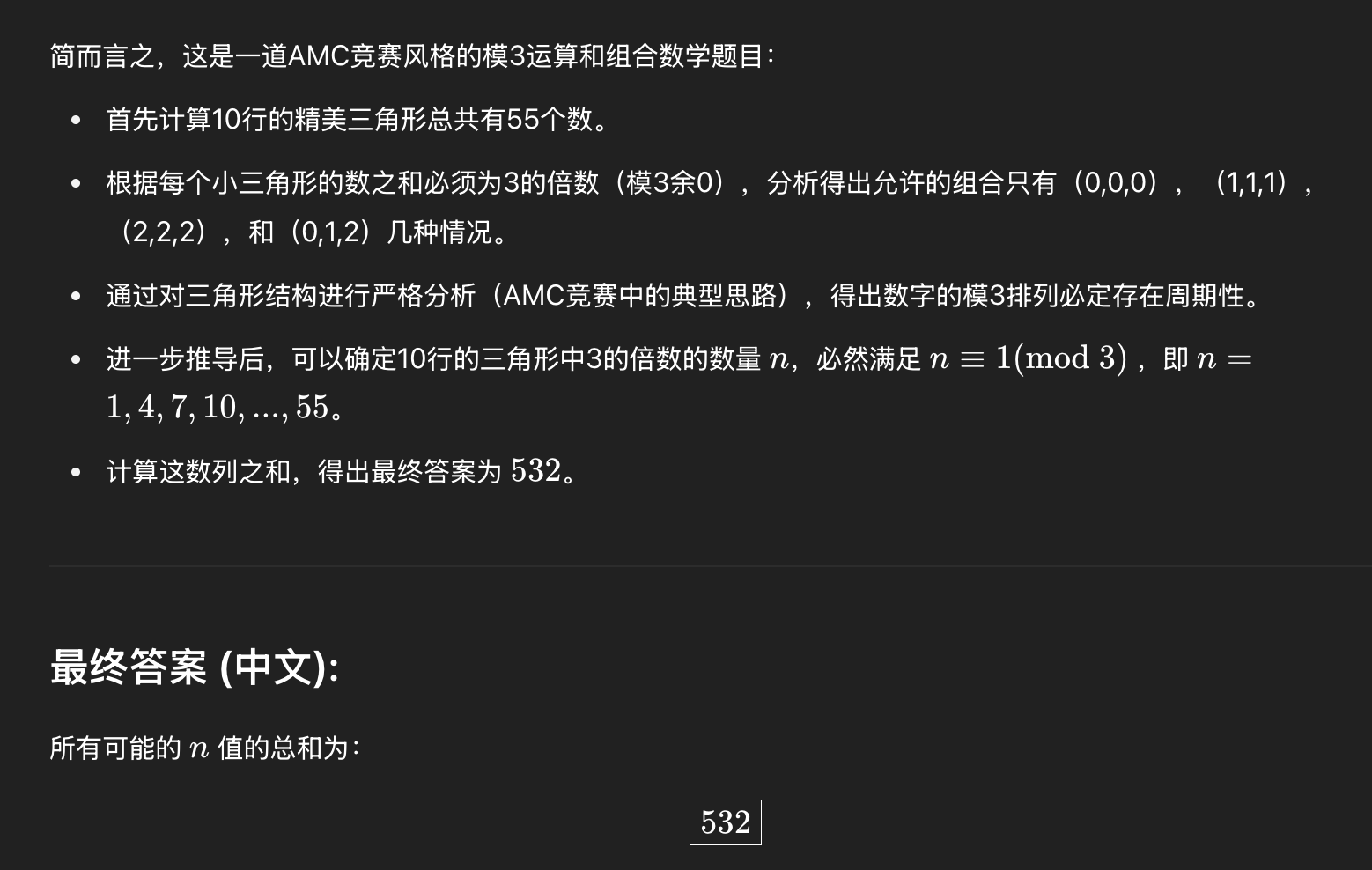 我已经无力吐槽了
我已经无力吐槽了